CMU 11642 的课程笔记。文档的表示形式不只词袋一种,它可以有 fields,有 hierarchical structure(XML),multiple representations of meaning, priors 等形式,这一章讲的就是检索模型怎么来处理这些复杂的文档表达。
Multiple representations of meaning
Fields can be used to provide different representations of the same information
三种表达方法。
- Vector space
– 每个 representation 提供独立的 ranking score
– 对每个分数求平均来得到一个最终的 ranking - Okapi
– Representations 以不同的方式来表达相同含义
– 合并 representations 来得到一个更好的 representation - Indri
– 每个 representation 提供一个 p(t|d) 的估计
– 有多种方法来合并这些估计
Vector space
Option 1: 一个词袋模型,包含了各种 filed 词汇
E.g., iPad::inlink, iPad::title, iPad::body, …
这让 length normalization 变得更为复杂,比如说 inlink text 可能会和 title 或者 body text 混在一起。一般不用这种方法。
Option 2: Several vector spaces
$w_{title} *sim(query,title_i) +$
$w_{body} *sim(query,body_i) +$
$w_{inlink} *sim(query,inlink_i) +$
$w_{url} *sim(query,url_i) $
这种方法易于管理,也易于扩展,Lucene 也采用了这种方法,然而关于怎么设置 weights,并没有什么 guidance。
Okapi
Evidence from each field should be weighted differently
一些 field 可能有更好的表达能力,如 inlink text,一些 field 可能更为冗长,如 body,所以不同的 fields 我们应该区别对待。
One solution
• 把 query 看作 |F| 个词袋
• 对 query 匹配每个 field,然后 add the score
然而 … 这打破了 BM25’s saturation assumption。在 |F| 个 field 里中出现了一次的字段,比在一个 field 里出现了|F|次的字段,有更大的影响,这并不是我们想要的。
Solution: 用一个复合加权的 representation,一篇文档就用一个词袋
$$tf_t=\sum_fw_ftf_{t,f}$$
$$doclen=\sum_fw_fdoclen_f$$
F: the set of fields
-> 然后用标准的 BM25
但是 … BM25 有常量,可能我们需要 tune them on a per-field basis,可以用 BM25F。
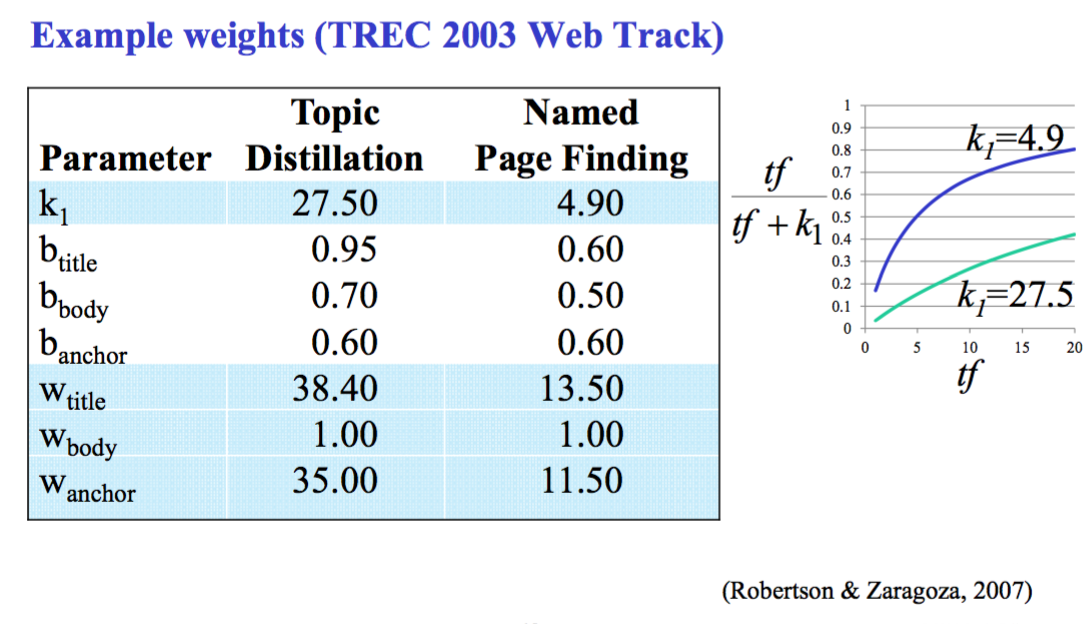
特性:
- 一个 vocabulary 涵盖了所有的 fields
– 所以一个 term 有一个 global idf, 而不是一个 field-specific idf
– 对各种文档都有适用么?» E.g., 专利,医疗记录等 - Field-specific tuning
- constants 的影响很难理解
Indri
Indri 模型。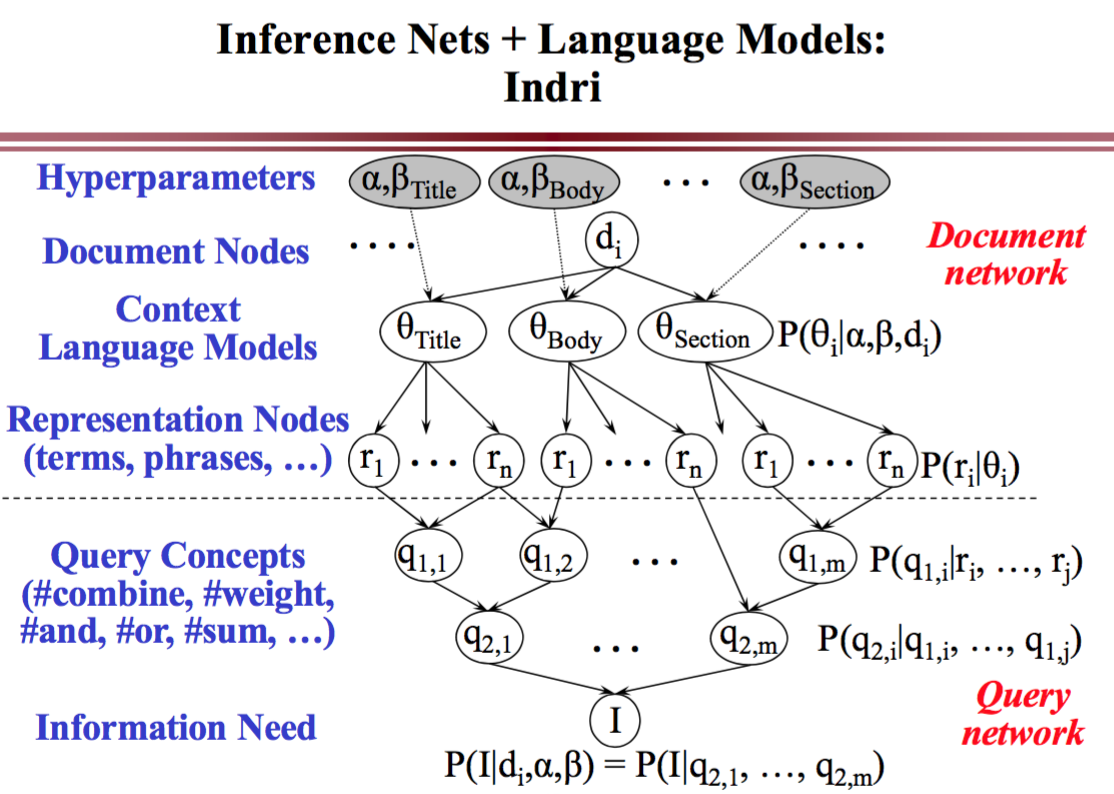

#AND 和 #WAND 用来合并独立的概率
#SUM 和 #WSUM 用不同方法来估计同一个概率
Hierarchical structure(XML)
Hierarchical structure 的文档通常用 Bayesian inference networks 来解决,如 indri。
首先对 flat 和 hierarchical structure 做一个区分。
Flat
元素之间是相互独立的,一个 term 只在包含了它的那个元素(通常是一个)里出现。
检索目的通常是一篇文档。
Hierarchical
元素之间是相互关联的,通常是包含的关系,一个 term 在所有包含了它的元素里出现。
检索目的可以是文档,也可以是元素。
Issues
检索什么样的 element?
• Document? Encounter? Diagnosis?
用怎样的 corpus statistics
• Document vs. element
怎样组合来自不同 elements 的 evidence
• Can we prefer patients that have several matching encounters?
Exact-match vs. best-match document structure
• 可能 query 并不能完全匹配文档结构
Ranking elements
One option: Use Jelinek-Mercer smoothing
$$P(q_i|e)=(1-\lambda)P_{MLE}P(q_i|e)+ \lambda P_{MLE}P(q_i|C)$$
这种方法可能带来的问题是:
- 文档结构不规范,这种情况经常在 web 文档中出现,如果文档里本来包含了 query term 然而因为文档不规范而找不到相应的 element,那么 score 可能为 0。
- query 可能太严格。
– #AND[title](iphone):不匹配 “Apple Cuts Phone Price”
– #AND[paragraph](solutions to poverty): “poverty” 和 “solutions” 可能出现在不同的段落里
解决方案是,多加一个 smoothing。
Multiple elements
这里我们探讨右图的情况。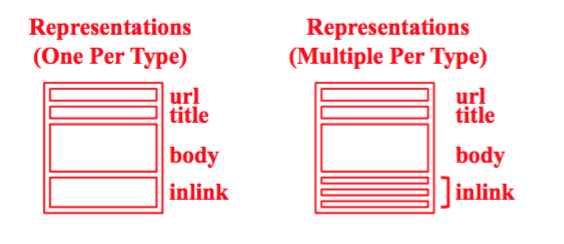
两种方法 Aggregation OR Combination。
- Aggregation: Combine inverted lists
- Combination: Combine scores
Aggregation
Indri 允许在 query 里指定 aggregation type
- term.element
– 如果没有指定 element, 那么默认 element 为 Document
– Example: apple.inlink - 结果: 一个 inverted list 包含了一个 element 的所有 instance
Example
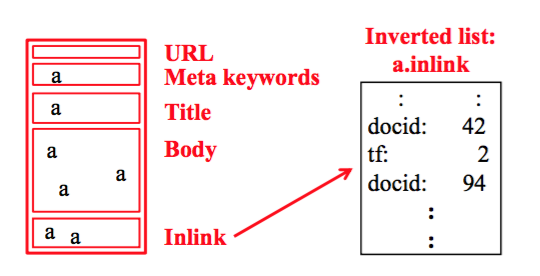
问题:
对这一个查询,用 Aggregation 的话以下两篇文档会得到一样的分数,然而其实 D2 要比 D1 更相关。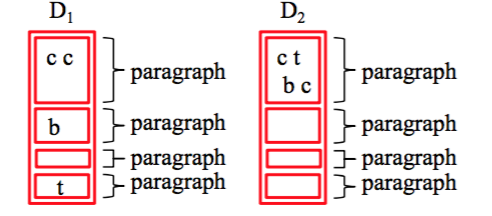
Combination
用 #MAX, #SUM, #OR 等 query operators 来合并 element scores。
首先我们来认识一下 query。
E.g.1
最外面的 element 是 document, 所以对 documents 进行排序
- 对每个 sentence 进行 #AND (breast cancer treatment) 运算,结果是一个 (sentence, score) 列表
- 对上一步产生的结果 #SUM 运算,结果是一个 (document, score) 列表
E.g.2
最外面的 element 是 paragraph, 所以对 paragraphs 进行排序
- 对每个 sentence 进行 #AND (breast cancer treatment) 运算,结果是一个 (sentence, score) 列表
- 对上一步产生的结果 #SUM 运算,结果是一个 (paragraph, score) 列表
来考虑下不同的 combine query operator 产生的影响。
#MAX[document] (#AND[sentence](breast cancer treatment) )
– 只考虑 best sentence
#SUM[document] (#AND[sentence](breast cancer treatment) )
– poorly matching sentences 会让分数变低
#OR[document] (#AND[sentence](breast cancer treatment) )
– 偏好有更多匹配的 sentences 的文档
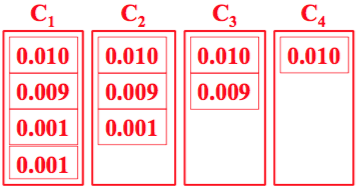
• #MAX considers them equal
• #AND prefers C4
• #OR prefers C1
• #AVERAGE prefers C4
Comparsion
假定目标是检索有 paragraphs 讨论 breast cancer treatment 的文档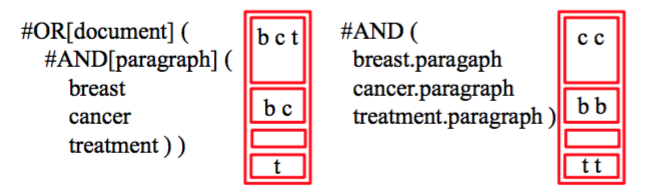
Combination: Partial credit for sections that partially match
Aggregation: The terms might not all be in the same section
Extents
Using extents as evidence
• 检索的是 document
• 偏好 ‘iraq’ and ‘war’ 在同一句话里的文档
– 出现在 title 里会让分数有稍稍的提高,因为有 smoothing
Using extents as a constraint
• 检索的是 document
• 要求 ‘iraq’ and ‘war’ 必须出现在同一句话的文档
– 出现在文档的其它部分并不会有任何帮助
HLT Applications
文档结构可以由 annotation processes 产生
• E.g., named entity annotators, semantic role labelers, …
Retrieval of elements, using semantic role annotations
• ./element specifies that element is a child of the parent field
Table retrieval
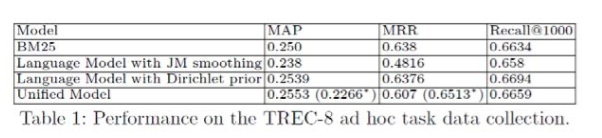
实际就是一个把 table 转化为 structure document 的问题。
Summaries
Fields
• 用于 independent evidence (author, title, journal, …)
• 用于 multiple representations (url, title, body, …)
• 了解差异
• 了解各个检索模型如何支持这些 fields
• 了解在 query 中如何使用这些 fields
Hierarchical structure
• 怎样在多个 elements 都有匹配时 combine evidence
• Exact-match vs. best-match document structure
• 了解 Indri 怎样支持这些 elements
• 了解在 query 中如何使用这些 elements

